D4. Разбиение на невозрастающие слагаемые, лексикографический порядок
Ограничение времени 1 секунда
Ограничение памяти 64Mb
Ввод стандартный ввод или input.txt
Вывод стандартный вывод или output.txt
Дано натуральное число N. Рассмотрим его разбиение на натуральные слагаемые. Два разбиения, отличающихся только порядком слагаемых, будем считать за одно, поэтому можно считать, что слагаемые в разбиении упорядочены по невозрастанию.
Формат ввода
Задано единственное число N. (N ≤ 40)
Формат вывода
Необходимо вывести все разбиения числа N на натуральные слагаемые в лексикографическом порядке.
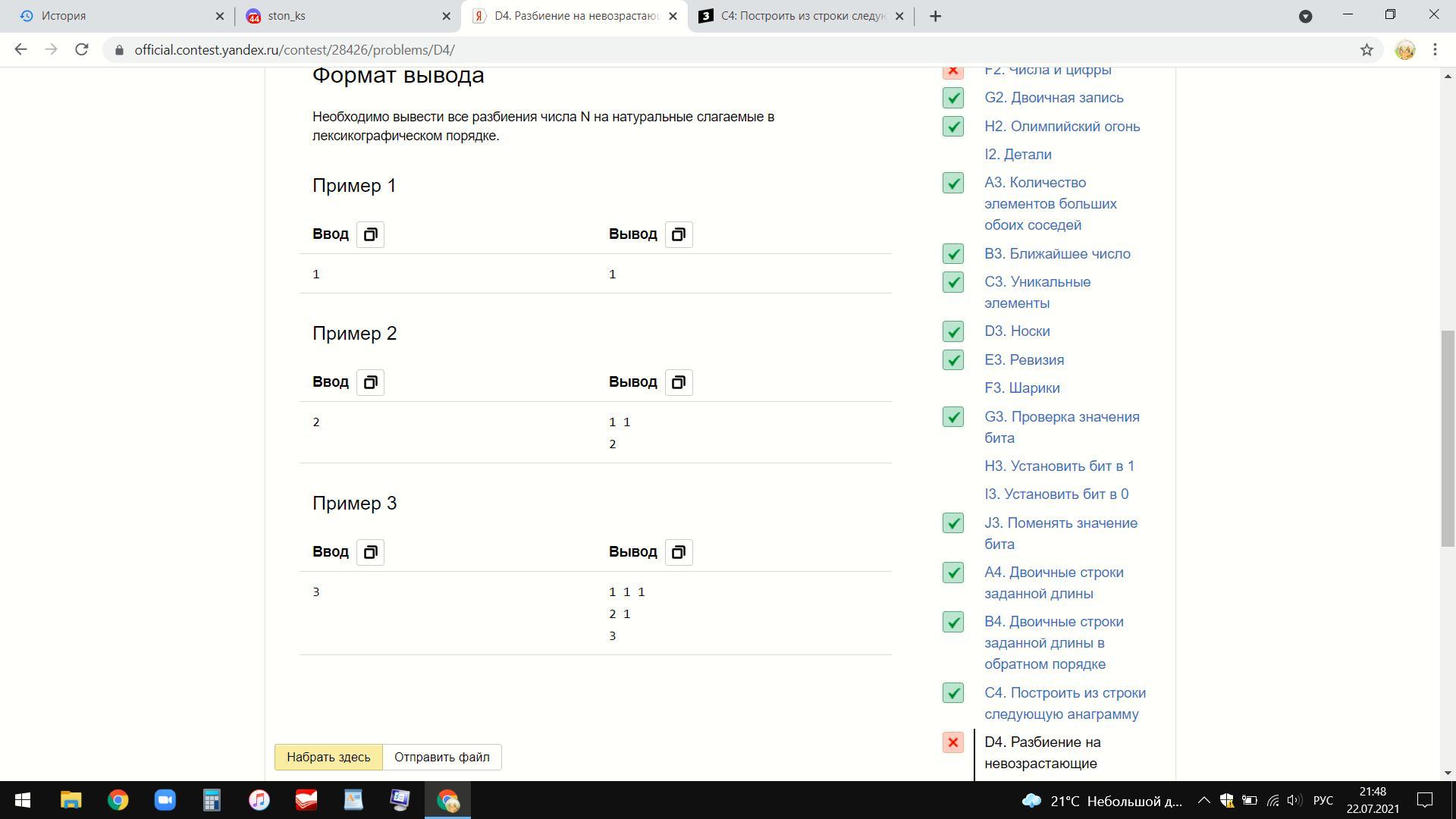
Ответы
На самом деле изначально здесь была другая задача. Вот ее условие:
C4. Построить из строки следующую анаграмму
Ограничение времени 1 секунда
Ограничение памяти 64Mb
Ввод стандартный ввод или input.txt
Вывод стандартный вывод или output.txt
Для данного слова (последовательности строчных латинских букв) выведите следующее за ним (в лексикографическом порядке) слово, которое может быть получено из данного перестановкой букв (анаграмму). Если данное слово уже является последним среди всех своих анаграмм, то необходимо вывести первую возможную (в лексикографическом порядке) анаграмму.
Формат ввода
Задана последовательность слов, по одному слову в строке. Длина одного слова не превышает 50 символов.
Формат вывода
Необходимо вывести результат для каждого полученного на вход слова.
Ниже программный код:
#include <iostream>
#include <string>
#include <algorithm>
using namespace std;
int main() {
string word;
char for_sort[51];
int count_for_sort, min_def, min_def_index;
while (cin >> word) {
count_for_sort = 0;
min_def = 98;
min_def_index = 51;
for (int i = word.size() - 1; i >= 0; i--) {
for_sort[count_for_sort] = word[i];
count_for_sort++;
if (word[i] < word[i + 1])
break;
}
int shift = 0;
if (word[word.size() - count_for_sort] < word[word.size() - count_for_sort + 1]) {
for (int i = 0; i < count_for_sort; i++)
if (for_sort[i] - word[word.size() - count_for_sort] > 0 &&
for_sort[i] - word[word.size() - count_for_sort] < min_def) {
min_def = for_sort[i] - word[word.size() - count_for_sort];
min_def_index = i;
}
swap(for_sort[0], for_sort[min_def_index]);
shift = 1;
}
sort(for_sort + shift, for_sort + count_for_sort);
for (int i = word.size() - count_for_sort; i < word.size(); i++)
word[i] = for_sort[i - word.size() + count_for_sort)];
cout << word << endl;
word.clear();
}
return 0;
}