Дан массив из 20 случайных чисел от 1 до 10. Вывести в консоль самое часто встречающееся число или список чисел.
Пример: [1, 2, 6, 5, 3, 2, 7]
Самое частое число - 2
Ответы
Ответ:
Рассмотрим решение на языке Python
Объяснение:
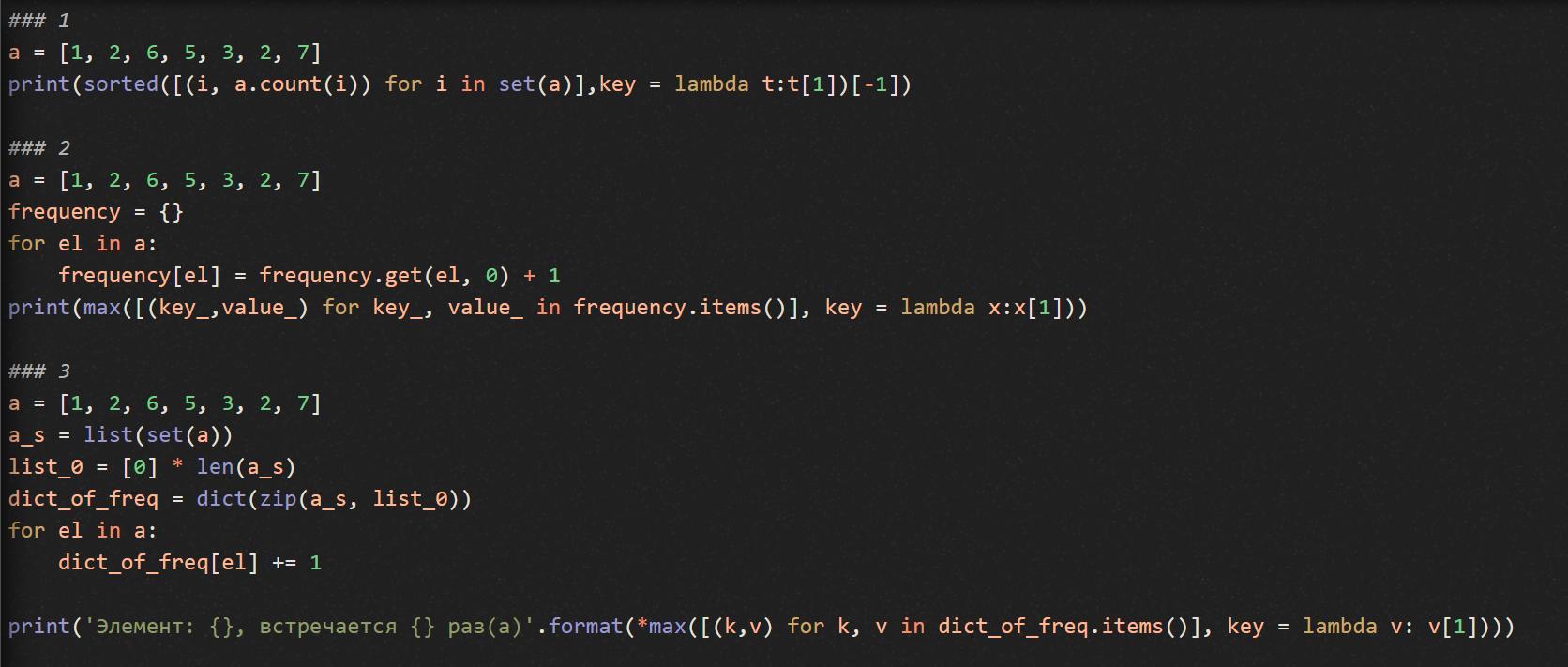
Первый способ
Отсортируем имеющийся список как показано.
Получим кортеж, где есть два значения: key и value.
Первое число - собственно, элемент. Второе число - количество раз.
Второй способ
Создадим словарь и будем считать количество элементов.
Выведем второй элемент кортежа максимального значения
Третий способ
Создадим словарь, множество, список ключей.
Как и во втором способе, пройдемся по элементам и будем увеличивать счетчик на 1.
Выведем с помощью метода format, чтобы было красиво.
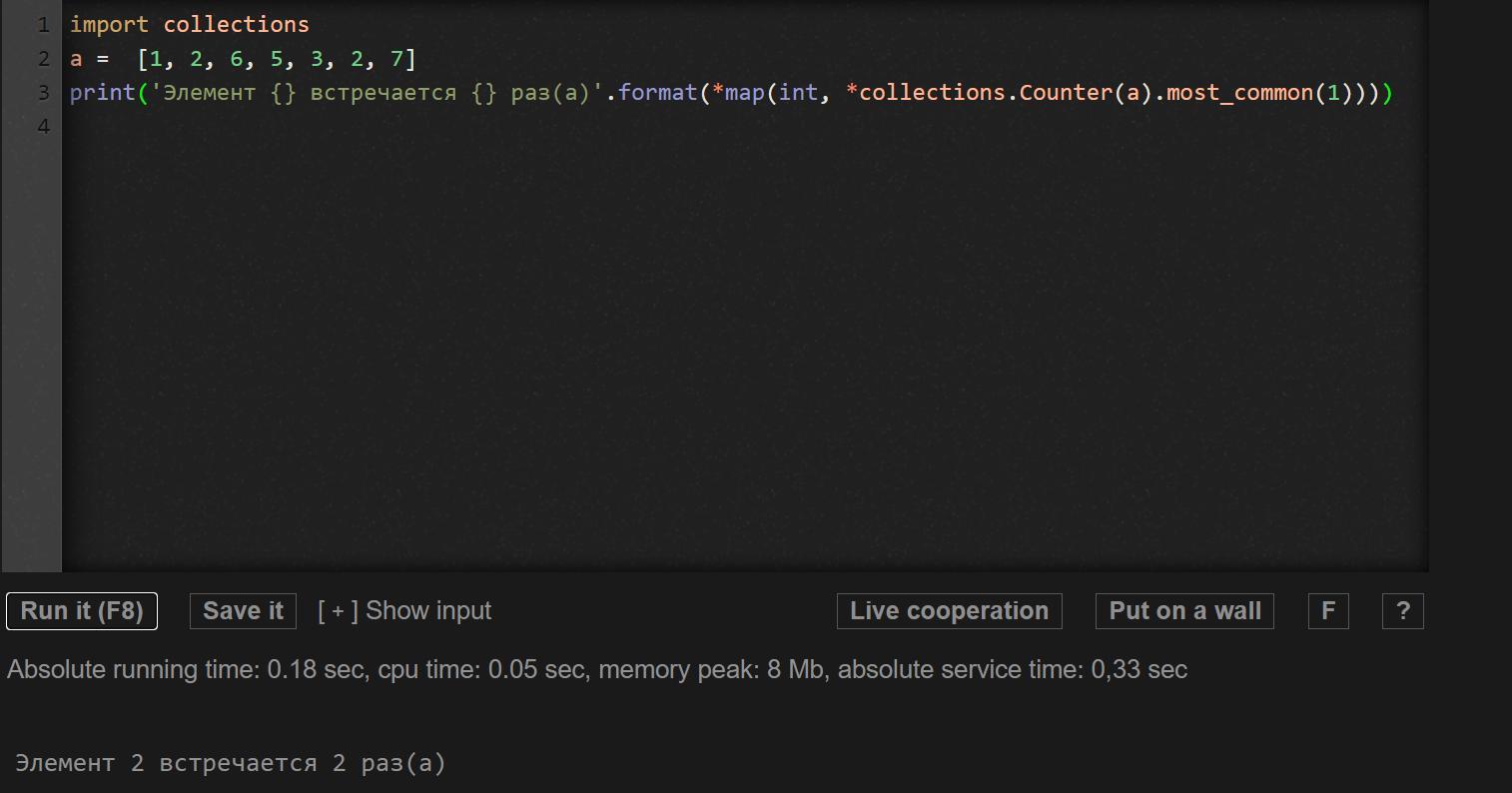
Четвертый способ
Самый простой, и тем не менее, правильно работающий. Используем библиотеку collections, откуда возьмем тип данных Counter - словарный тип, используемый для подсчета объектов.
Приведу пример на Haskell.
- import Data.List (group, groupBy, sort, sortBy, unfoldr)
- import Data.Function (on)
- import System.Random
- getFreq :: [Int] -> [Int]
- getFreq xs = last $ [[fst zs | zs <- ys] | ys <- groupBy ((==) `on` snd) . sortBy (compare `on` snd) $ [(head x, length x) | x <- group . sort $ xs]]
- randomList :: Int -> (Int, Int) -> IO [Int]
- randomList 0 _ = return []
- randomList n range = do
- r <- randomRIO range
- rs <- randomList (n-1) range
- return (r:rs)
- main :: (Int, Int) -> IO()
- main range = do
- rs <- randomList 20 range
- print rs
- print $ getFreq rs
Здесь алгоритм поиска наиболее часто встречающихся чисел последовательности реализован в функции getFreq. В ней мы исходный массив сортируем и группируем соседние элементы по значению. Затем формируем список из кортежей (число, частотность) и сортируем по возрастанию частотности. Затем группируем соседей по частотности, выделяем только значения, без указания частотности и берем последний элемент – самая большая частотность. Этот элемент – список из самых часто встречающихся элементов.
