Предмет: Английский язык,
автор: пупсяра1
помогите пжпжпжпжппжжпжпжпжпжппжпжжп
Приложения:
Ответы
Автор ответа:
0
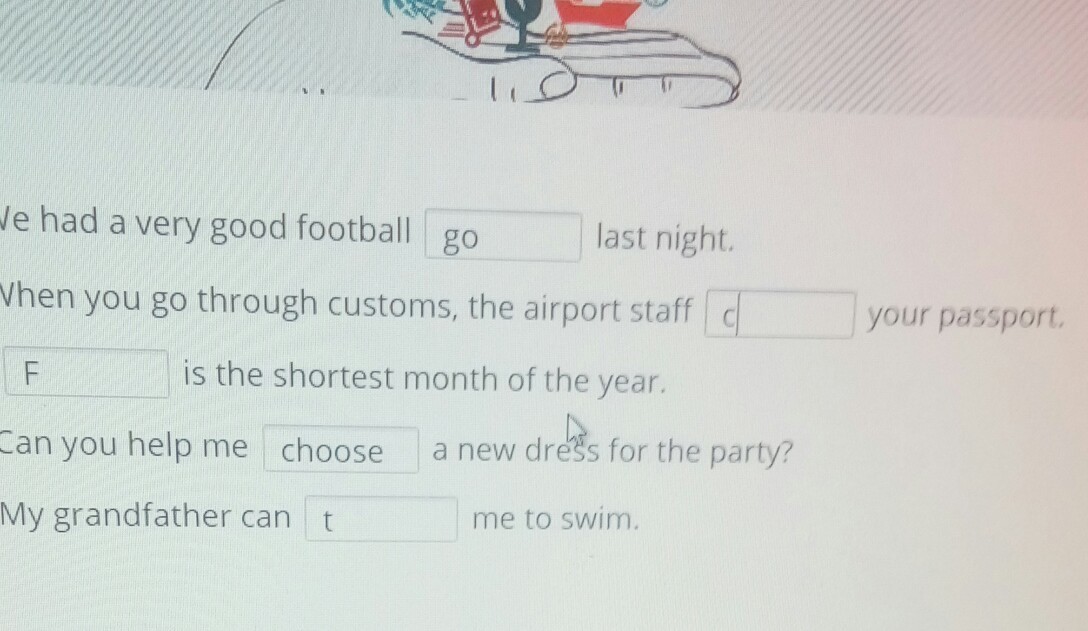
We had a very good football game last night.
When you go through customs the airport staff checks your passport.
February is the shortest month of the year.
My grandfather can teach me to swim.
When you go through customs the airport staff checks your passport.
February is the shortest month of the year.
My grandfather can teach me to swim.
Похожие вопросы
Предмет: Українська мова,
автор: petrukelizaveta7
Предмет: Математика,
автор: maksonpokemon28
Предмет: Кыргыз тили,
автор: Аноним
Предмет: Литература,
автор: slava34689
Предмет: Биология,
автор: Dimka2020997